
瞄准AI、图形顶端战场:摩尔线程上演国产GPU硬核实力路演
瞄准AI、图形顶端战场:摩尔线程上演国产GPU硬核实力路演这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
来自主题: AI资讯
9292 点击 2025-12-22 17:06
 搜索
搜索
这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。

刚刚,梁文锋入选《自然》2025年度十大人物榜单!Nature给出的评语是:科技颠覆者!正式报道中,则用「这位中国金融奇才的DeepSeek AI模型惊艳了世界」。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。

DeepSeek 一发布模型,总会引起业内的高度关注与广泛讨论,但也不可避免的暴露出一些小 Bug。

DeepSeek V3.2的Agentic能力大增,离不开这项关键机制:Interleaved Thinking(交错思维链)。Interleaved Thinking风靡开源社区背后,离不开另一家中国公司的推动。
就在前天,DeepSeek 一口气上新了两个新模型,DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。
昨天,DeepSeek 在 GitHub 上线了一个新的代码库:LPLB。
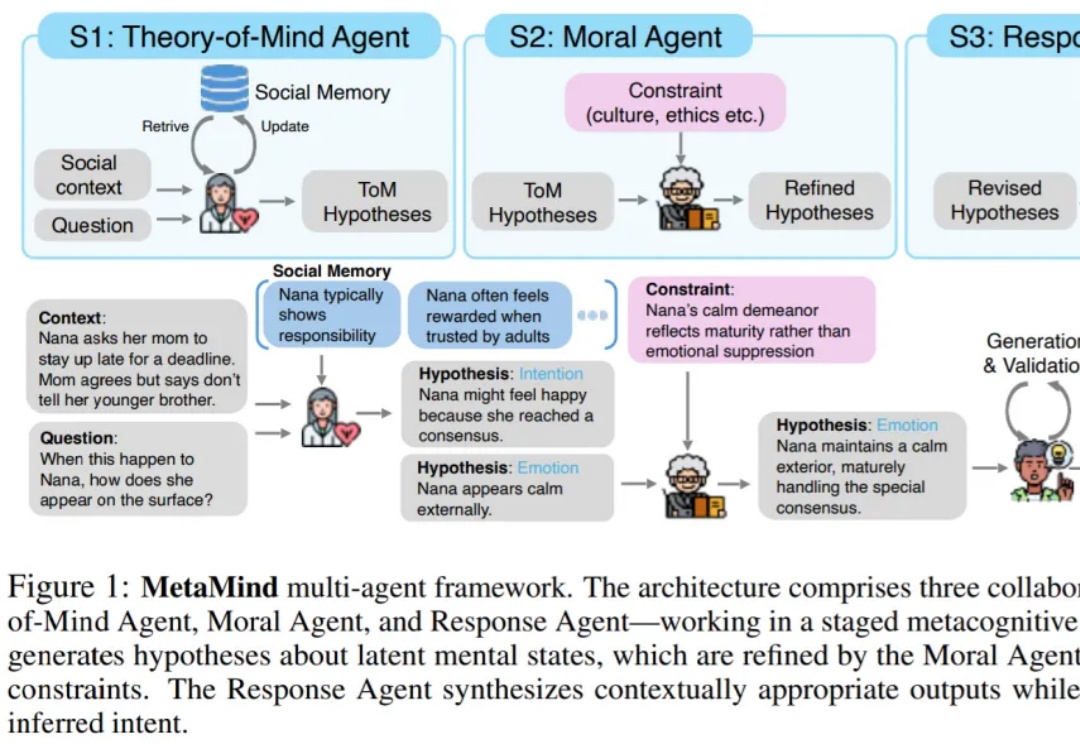
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice